【Feed43】RSS配信非対応のサイトでRSSフィードを取得する方法

この記事では、RSS非対応のサイトで、RSSフィードの受信をできるようにするサイト「Feed43」について書きます。
※2023年4月時点で、サービスが廃止され、アクセスできなくなりました。これまで「Feed43」で作成したRSSフィードも受信できないようになっています。
RSSを配信していないサイトで、強制的に独自のRSSフィードを作成できるサイトです。RSSフィードを作成して購読することで、RSS対応サイトと同じようにフィードリーダーでお知らせの受信、内容の確認ができるようになります。
以下のステップで作成できます。
- サイトを入力
- HTMLが表示されるので、受け取りたい更新情報を抜粋して登録
- RSSのリンクが作成されるので、購読登録する
フィードタイトル、どの部分を説明や日付に組み込むか等を、細かく設定できます。HTMLを手動で抜粋しないといけないので、初心者さんには少しだけハードルが高いですが、パターンがあるので、その通りにやれば問題なくできると思います。
本サービスを使うことで、サイト運営者に通知がいくとか、そのサイトに何か悪影響を及ぼすといったことは一切ありません。自分だけで、こっそり通知を受け取るようにします。
ブログの更新情報をお知らせするサービスです。気になるサイトをRSSに登録(購読)すれば、自動的にチェックしてくれます。新しい記事が公開された時に、「この記事が投稿されたよ~」と通知してくれます。
購読というと少し有料っぽいニュアンスになりますが、無料です。
LINE通知のブログバージョンといったイメージです。デフォルトでは通知オフになっているので、RSSで購読して通知オンにしてやろう~ってことです。
フィードリーダーと呼ばれるフィードを読み取るアプリ、更新情報を受け取りたいサイトがRSSに対応していることが条件です。一度購読すれば、永久的に情報を取得してくれます。
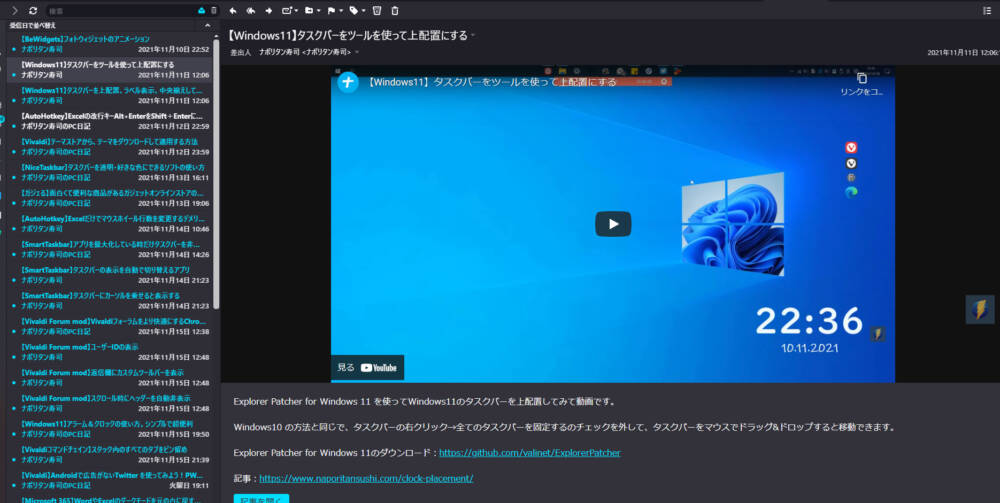
フィードを読み取るアプリは色々あります。僕は、Vivaldi(ヴィヴァルディ)ブラウザに標準内蔵しているフィードリーダーを利用しています。
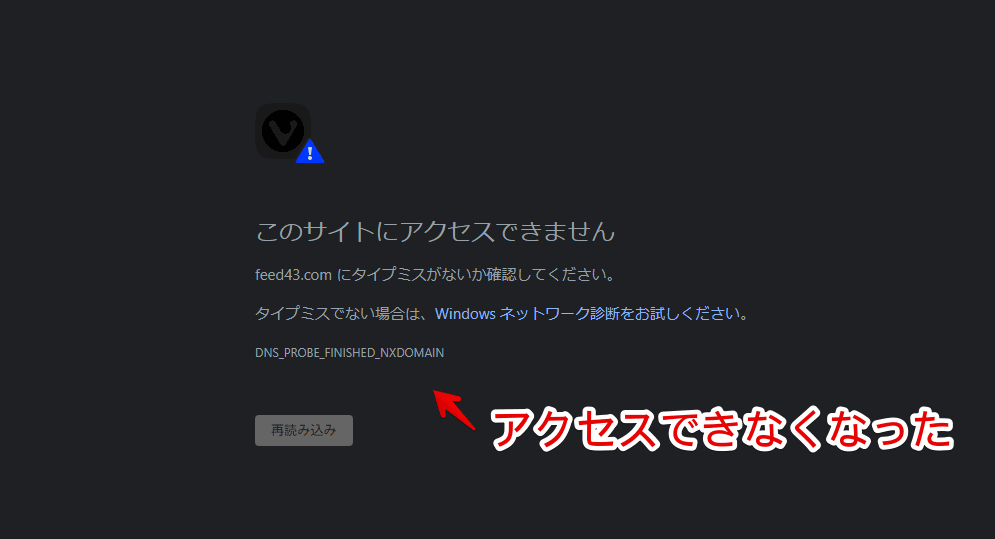
2023年に入ったくらいから、サイトにアクセスできなくなりました。Twitterで調べてみると、他にも同様のツイートが見られます。恐らく、サービスが終了してしまったと思います。
代替サイトとしては、「PolitePol」や「RssEverything」などが挙げられます。
リリース元:Plan43
アクセス方法
以下のサイトからアクセスできます。2023年4月時点で、サイトにアクセスできなくなりました。
使い方
大きく4ステップです。ステップ2が一番難しいです。
- サイトをFeed43に入力してみよう!
- HTMLを抽出してみよう!
- タイトルとかの設定をしよう!
- 購読してみよう!
Specify source page address(サイトの入力)
RSSフィードを作成したいサイトのURLをコピーします。試しに、クラファンガジェットについて紹介されていたサイト「spark gadget(※2023年4月現在、ブログをやめちゃったようです🥲)」のフィードを作成してみます。
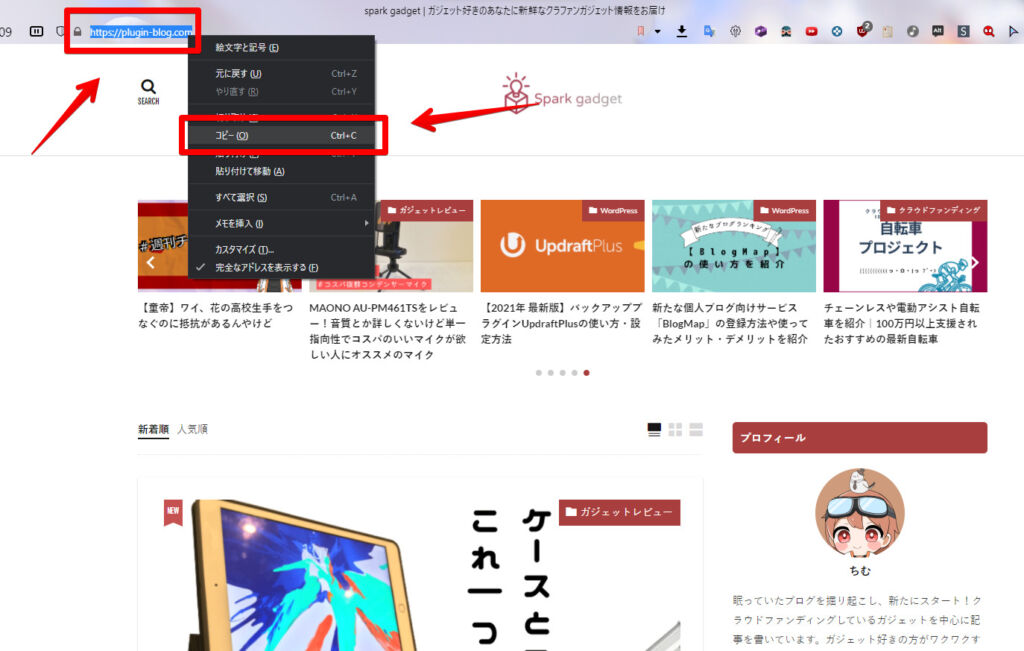
注意点ですが、トップページのアドレスをコピーします。記事のURLではなく、サイトのホームページです。上記サイトだと、以下の部分です。
https://plugin-blog.comRSSに対応しているサイトは、普通に購読したほうがらくちんです。例えば、当サイトはRSSに対応しているので、対応ブラウザで開くと、アドレスバー横にフィードボタンが表示されます。
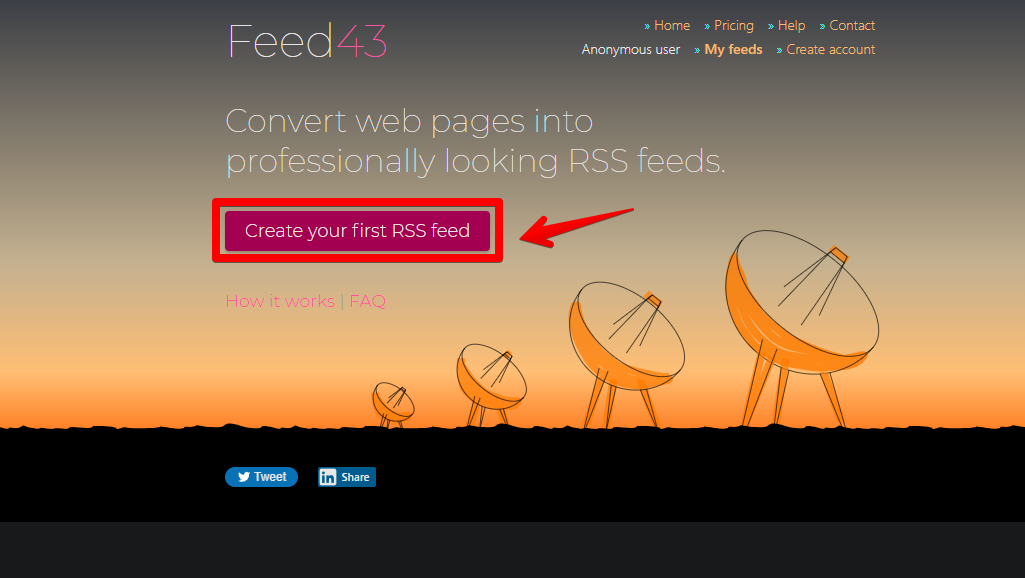
コピーできたら、「Feed43」にアクセスします。赤色ボタンの「Create your first RSS feed」をクリックします。
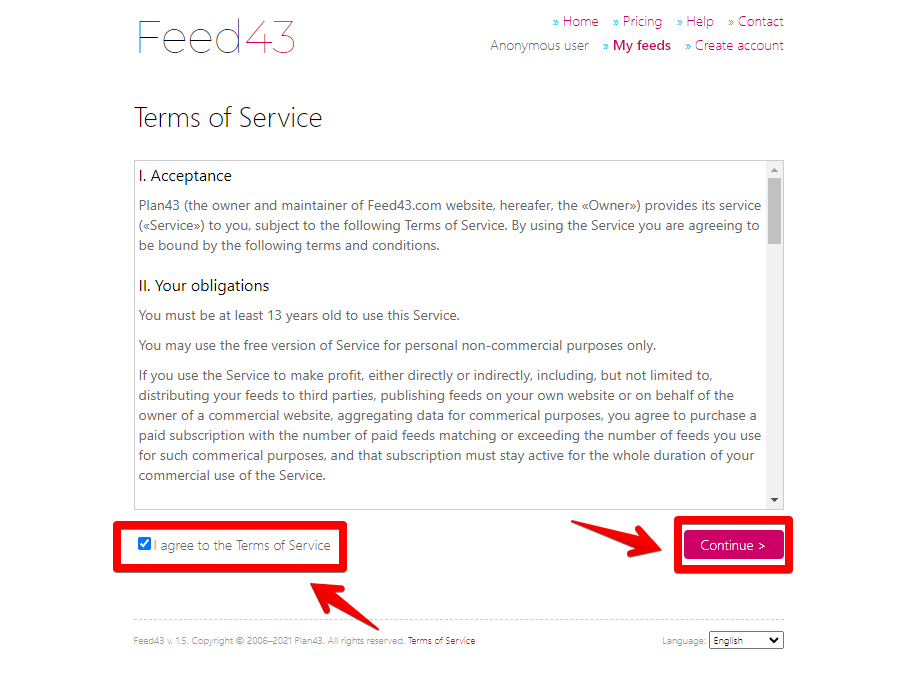
初回アクセスだと、利用規約が表示されます。「I agree to the Terms of Service(サービス規約に同意する)」にチェックを入れて「Continue」をクリックします。
「Address」の部分に、先ほどコピーしたサイトのURLを貼り付けます。「Reload」をクリックします。
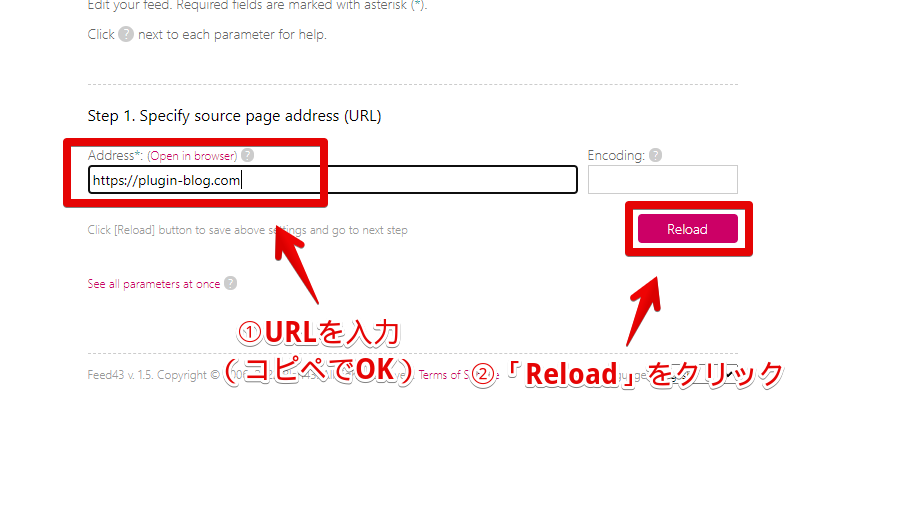
「Encoding」には何も入力しなくても、OKです。自動的に正しい文字コード(一般的には、「utf-8」)を取得してくれます。サイトのHTMLがずらっと表示されます。続いて、ステップ2で取得したいフィード部分を抽出していきます。
Define extraction rules(HTMLの抜粋)
「Page Source」の部分に、トップページのHTMLが表示されます。
記事タイトル、記事リンク、場合によって日付といったようなパターンが連続している部分を探します。見つけたら、その部分だけをコピーして、「Item (repeatable) Search Pattern」に貼り付けます。
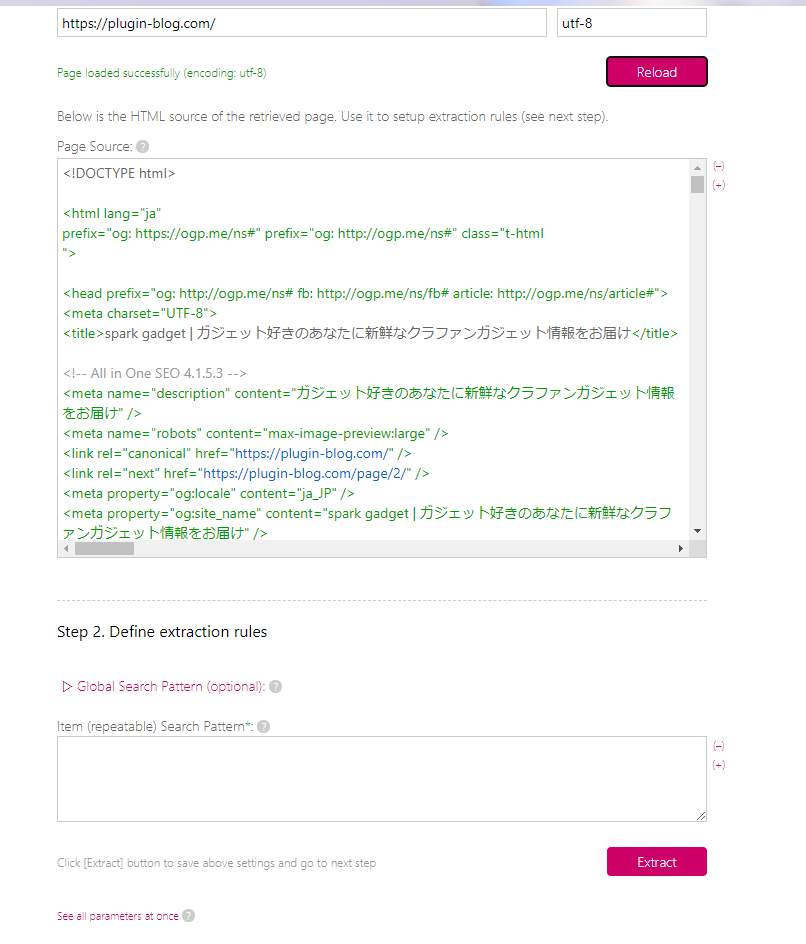
具体的に解説していきます。以下のようなパターンを探します。「<h2>」は、赤文字で書かれているので見つけやすいかと思います。
<h2 class="〇〇〇"> <a href="〇〇〇">〇〇〇</a> </h2>意味は、以下のようになっています。
<!-- 記事タイトル -->
<h2>〇〇〇</h2>
<!-- 記事リンク -->
a href=〇〇
<!-- サムネイル画像(アイキャッチ画像) -->
img src=〇〇HTMLと呼ばれるサイトを構築している重要なものです。普段は目に見えないので、初めて見る人も多いかと思います。とりあえず、サイトの裏側で頑張ってくれてる文字って認識でOKだと思います。
「spark gadget」サイトだと、以下の部分が該当します。
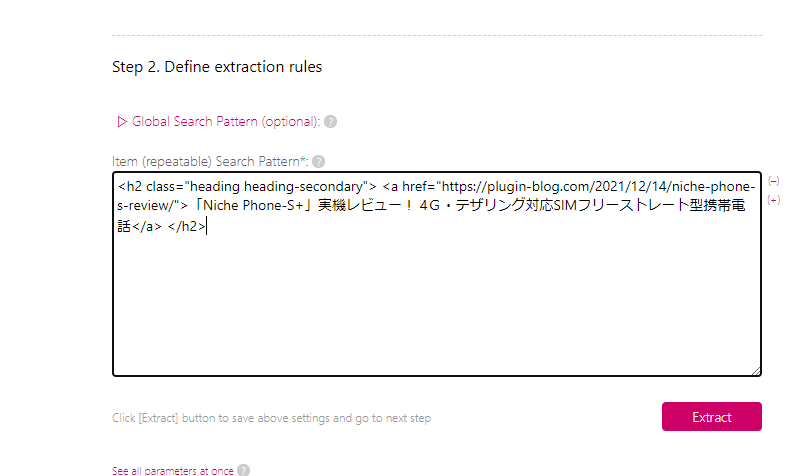
<h2 class="heading heading-secondary"> <a href="https://plugin-blog.com/2021/12/25/okami-review/">【iPadケースOkamiレビュー】ケースとスタンドが一つになったiPadケース</a> </h2>上記のような塊が、一定間隔ごとにあるはずです。「<h2>」の後には、日本語で記事タイトルが書かれています。
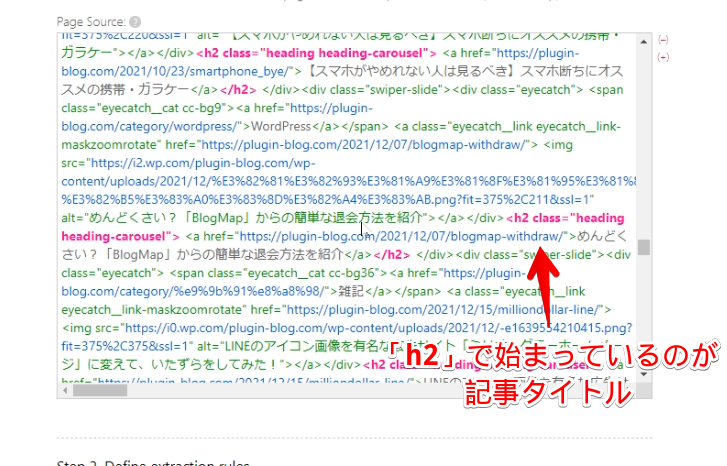
「</h2>」で終わっている部分までを、マウスで範囲選択してコピー(Ctrl+C)します。
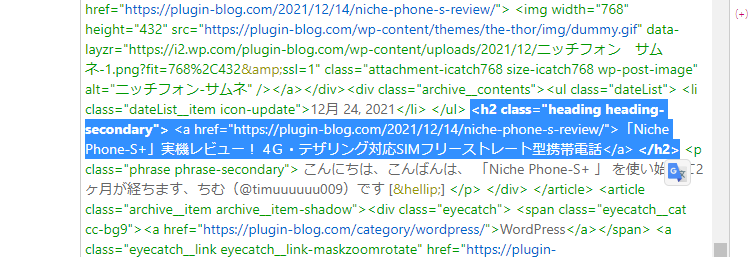
「Item (repeatable) Search Pattern(繰り返しパターン検索欄)」に貼り付けます。
変換作業をします。以下の形式に従って、各項目を書き換えます。
<!-- 記事タイトルや記事リンクなどの記事ごとで変わるもの -->
{%}
<!-- 改行 -->
{*}「spark gadget」サイトだと、以下のようになります。
<h2 class="heading heading-secondary"> <a href="{%}">{%}</a> </h2>
連続しているパターンを見つけて、コピペして、タイトルやリンクを「{%}」、改行されている部分を「{*}」にするという流れです。
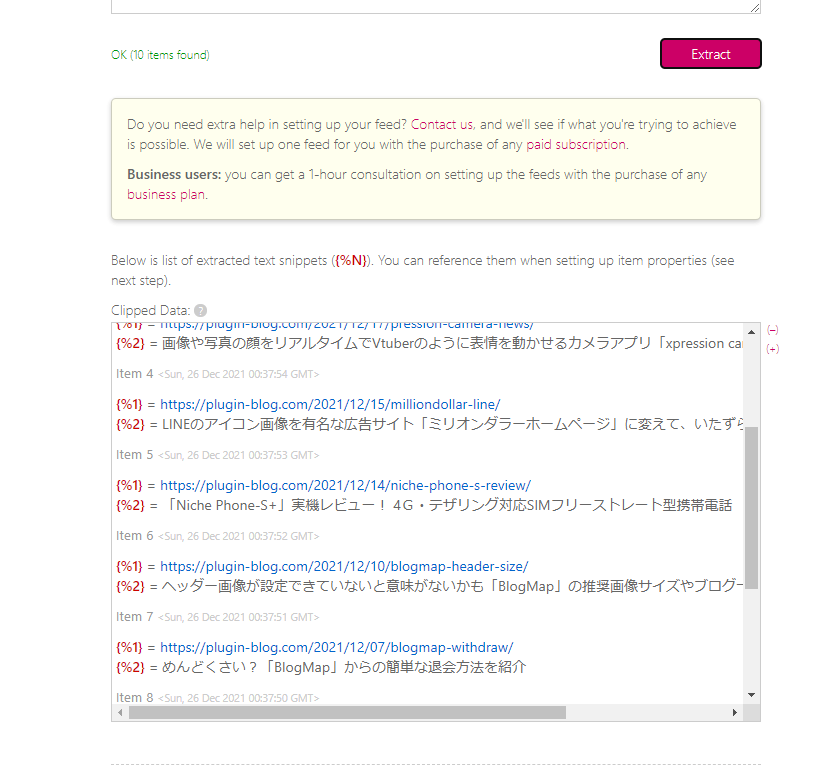
変換できたら、「Extract(抽出)」をクリックします。「Clipped Data」に、連続してそれぞれの記事タイトルが出力されたら成功です。「何も抽出されない」、「抽出されても1つだけ」といった場合は、失敗しているのでコードを見直します。
サイトによって、色々パターンが異なるので、いくつか例として複数のサイトを紹介します。変換後のコードも載せておきます。
色々なパターンを紹介するのが目的なので、元々RSSに対応しているサイトもあります。
ABlog | Ablazeメンバーによるブログ
HTMLの抽出
<h2 class="archive__title"><a class="archive__link" href="https://blog.ablaze.one/910/2021-12-20/">Floorp ブラウザ 8.1.1 リリースのお知らせ</a></h2><p class="archive__excerpt">Floorpでは安定したリリースと機能更新をできるように、Firefoxの通常版のリリースである Firefox Stable releaseに追従して…</p> </div>HTMLの変換
<h2 class="archive__title"><a class="archive__link" href="{%}">{%}</a></h2><p class="archive__excerpt">{%}</p> </div>Tanweb.net
HTMLの抽出
<a class="cardtype__link" href="https://tanweb.net/2021/12/20/44441/" data-wpel-link="internal">
<p class="cardtype__img">
<img src="https://tanweb.net/wordpress/wp-content/uploads/2021/12/ec-amazon-benrikensaku-520x300.jpg" alt="Amazon商品検索を超便利にする裏技!「割引率・価格帯検索」など商品選びの便利ワザ">
</p>
<div class="cardtype__article-info">
<time class="updated entry-time dfont" datetime="2021-12-20">2021.12.20 Mon</time>
<h2>Amazon商品検索を超便利にする裏技!「割引率・価格帯検索」など商品選びの便利ワザ</h2>HTMLの変換
<a class="cardtype__link" href="{%}" data-wpel-link="internal">{*}
<h2>{%}</h2>{*}上記サイトのように、記事リンクと記事タイトルの間に他の文字がある場合は、ごっそり変換の時に削除します。重要なのは、記事タイトルと記事リンクの2つだけです。
更新ログ HD Video Converter Factory Pro
サイト:https://www.videoconverterfactory.com/jp/hd-video-converter/update-logs.html
HTMLの抽出
<details>
<summary>- v21.8 2021年3月10日</summary>
<ul>
<li>1、100以上の新しいデバイスを追加しました。</li>
<li>2、変換数の問題を修正しました。</li>
<li>3、ハードウェアアクセラレーションの問題を修正しました。</li>
<li>4、変換とマージ機能の最適化。</li>
<li>5、バッチ変換での変換数の問題を修正しました。</li>
<li>6、8K動画の変換問題を修正しました。</li>
<li>7、ダウンロード数制限の問題を修正しました。</li>
<li>8、一部の動画サイトのダウンロード問題を修正しました。</li>
<li>9、ダウンロードしたファイルの命名問題を修正しました。</li>
<li>10、字幕のダウンロードに100以上の言語を追加しました。</li>
</ul>
</details>HTMLの変換
<details>{*}
<summary>{%}</summary>{*}
<ul>{*}
<li>{%}</li>{*}
</ul>{*}
</details>新着記事一覧 フリーソフト100
サイト:https://freesoft-100.com/recent-posts.html
HTMLの抽出
<a href="https://freesoft-100.com/review/okoshimax.html"><div class="post_block alternate"><div class="post_thumbnail" style="background-image:url(/img/sc1/sc33/okoshimax-51s.png);background-size:cover"> </div><div class="post_title">0.5~4倍速の速度調整、時間ごとのしおり機能などを利用して音声文字起こしを支援するソフト「OkoshiMAX」</div>HTMLの変換
<a href="{%}">{*}
<div class="post_title">{%}</div>{*}上記サイト様もいい練習になります。記事リンクと記事タイトルの間に、アイキャッチ画像などのフィードには不要なコンテンツがあるので、変換時に行を丸ごと削除しています。間を削除する時は、改行して、「{*}」を入れてあげるとうまくいきます。
Define output format(通知項目を設定)
うまく抽出されたら、続いてフィードの通知項目の設定です。
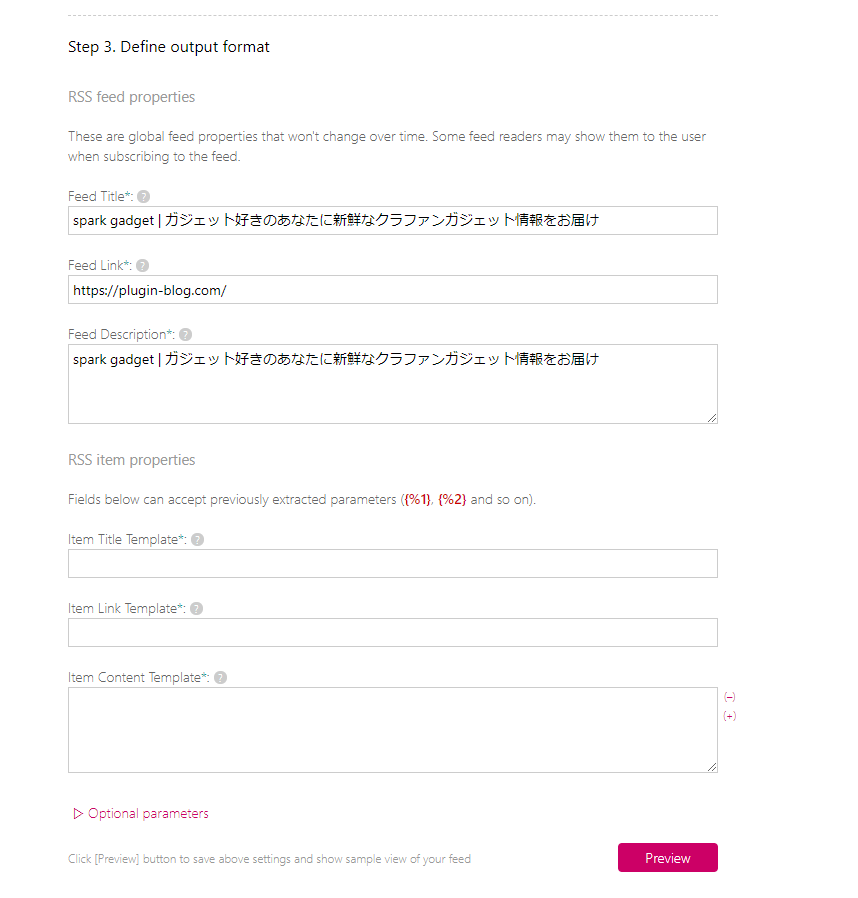
RSS feed properties
「RSS feed properties」は、フィードの全体設定です。既に抽出したサイトが登録されていると思うので、そのままでもいいですし、自分が分かりやすいように変換してもOKです。
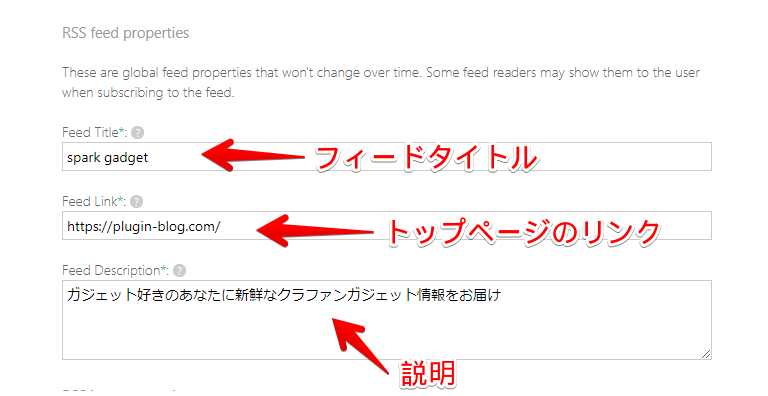
僕は、サイトタイトルを「spark gadget | ガジェット好きのあなたに新鮮なクラファンガジェット情報をお届け」から、「spark gadget」にしました。設定した名前で通知(RSS)が来ます。Vivaldiのフィードリーダーの場合、「差出人」という項目です。

RSS item properties
「RSS item properties」は、記事ごとの設定です。HTMLの抽出、変換の際に、パラメーターと呼ばれる値が作成されるので、それぞれの場所に入力します。
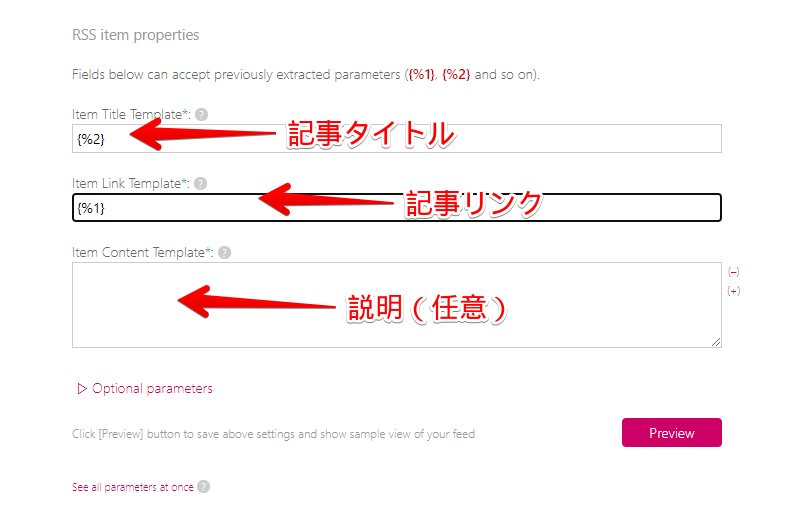
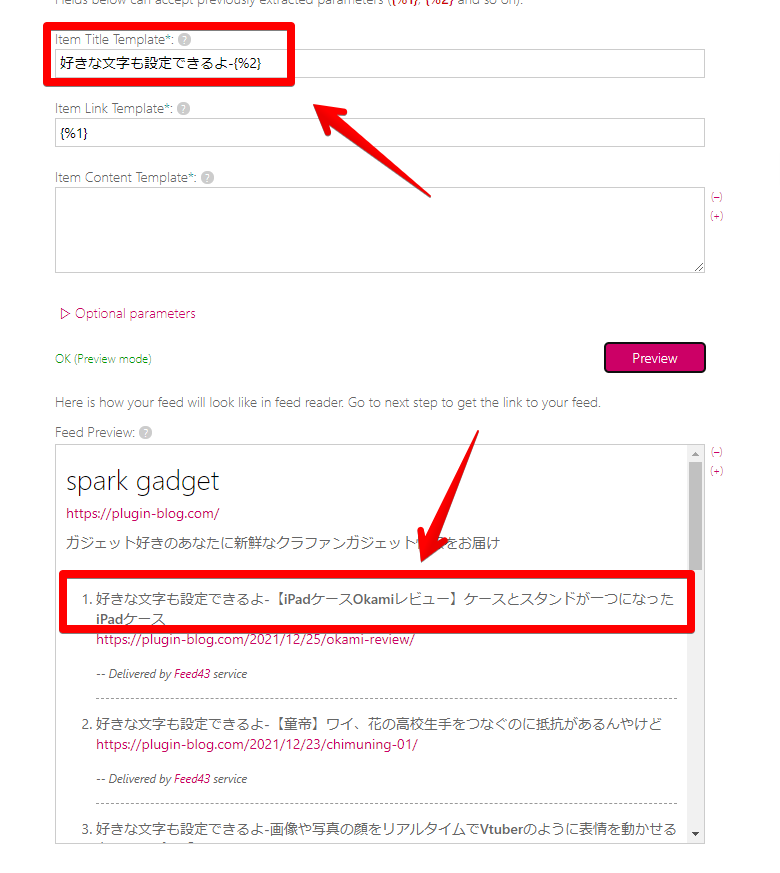
パラメーターは、抽出した際に表示されている「{%1}」や「{%2}」のことです。
例えば、下記画像だと「{%1}」は記事リンクなので、「Item Link Template」に入力します。「{%2}」は、記事タイトルなので「Item Title Template」に入力します。
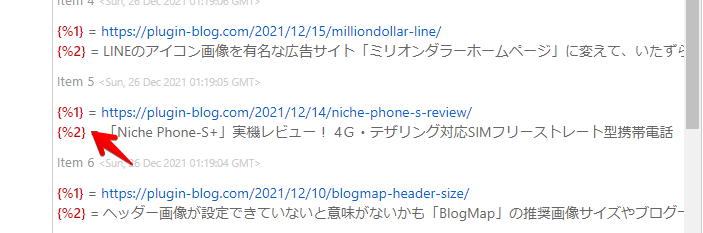
「Item Content Template(説明)」は、任意なので入力しなくてもOKです。例えば、記事の抜粋分を抽出していた場合は、こちらに記述します。「{%3}」などです。
サイト:Vivaldiのブラウザ専門ブログ – 最新ニュース、情報提供や Vivaldiの便利な使い方
本来は記事タイトルと記事リンクだけでいいのですが、以下のように抜粋分も抽出します。基本的には、「<p>~~</p>」で囲まれていると思います。
<h2 class="h4 entry-title"><a href="https://vivaldi.com/ja/blog/drop-big-tech-vivaldi-browser-and-lingvanex-bring-privacy-friendly-automatic-translations/">テキストを選択するだけでサイドパネルに翻訳を表示!言語学習にも便利なブラウザ内蔵の翻訳機能</a></h2><p class="date small">12月 2, 2021</p></header><div class="small"><p>デスクトップ版 Vivaldiに翻訳パネルが新登場。Vivaldi 5.0はデスクトップはもちろんノートパソコンでもご利用いただけます。</p>抜粋分部分を削除せずに、「{%}」で置き換えます。
<h2 class="archive__title"><a class="archive__link" href="{%}">{%}</a></h2><p class="archive__excerpt">{%}</p> </div>記事タイトル、記事リンク、抜粋分の3つ抽出するので、「{%3}」までのパラメーターが作成されます。
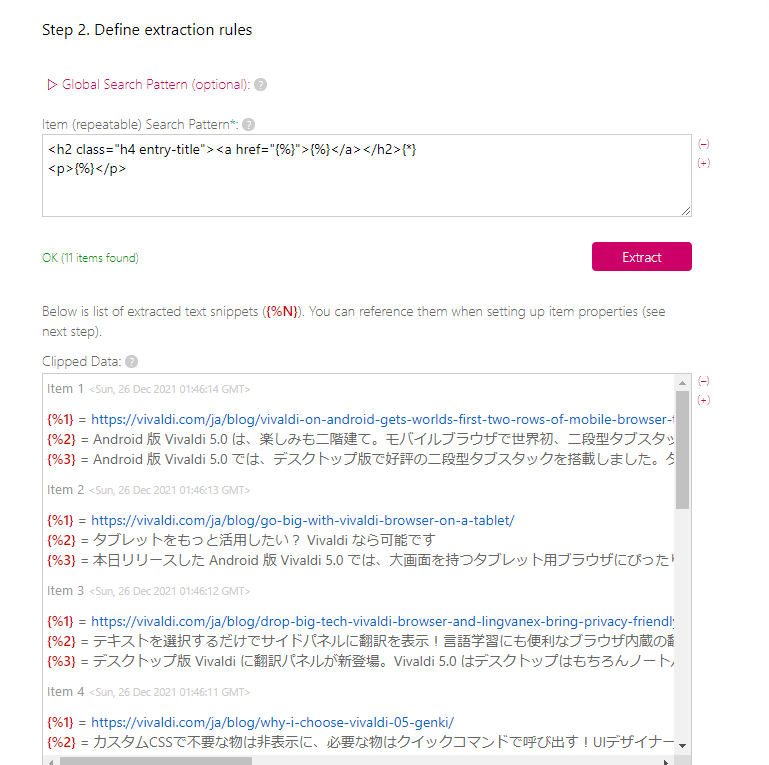
それぞれの項目にパラメーターを割り当てます。上記サイトの場合、Item Content Templateは、「{%3}」になります。
「Preview」をクリックすると、抜粋分を含めたフィードが作成されます。
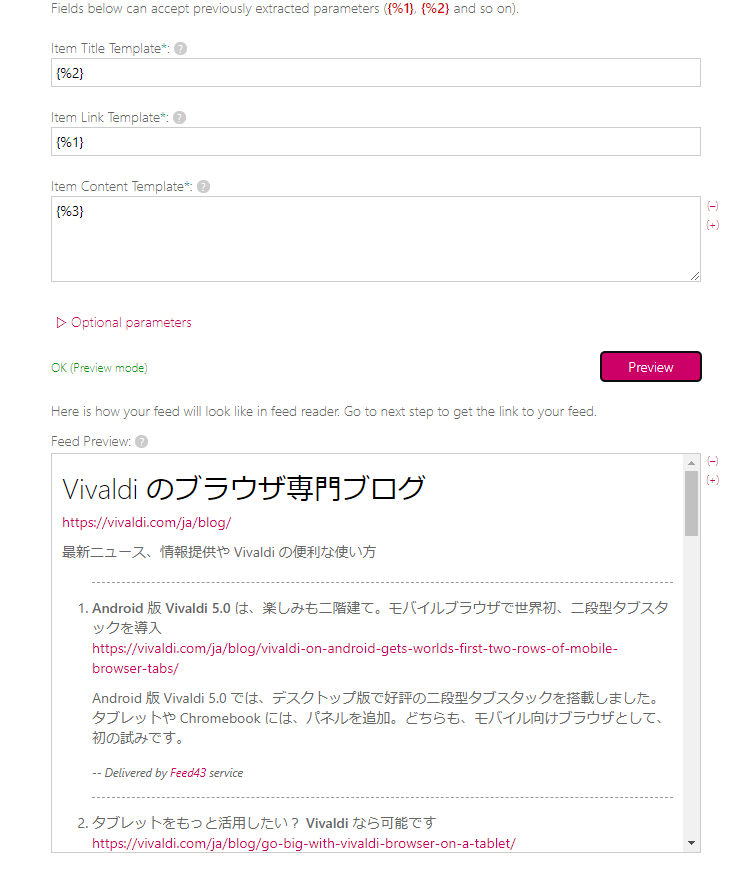
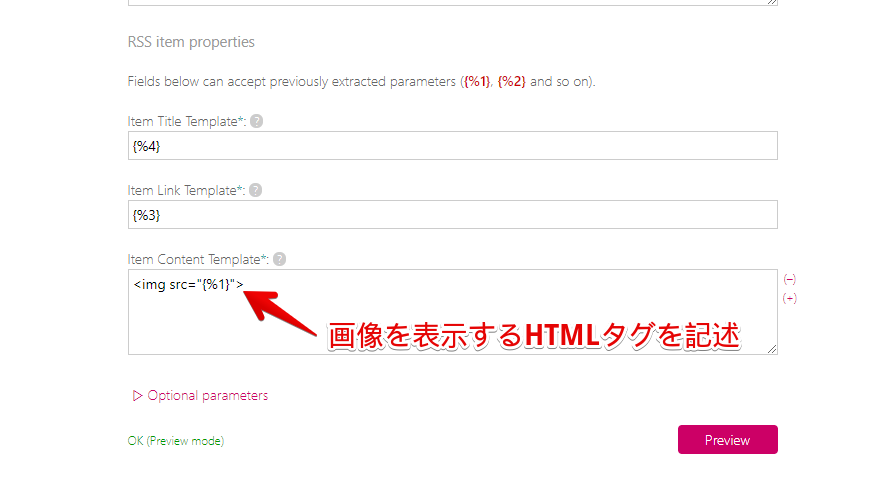
コメント欄にて教えていただきました。「Item Content Template」に、HTMLタグで画像を表示すると、サムネイル画像を取得できます。
<img src="{%数字}">ステップ2の「Define extraction rules」の時に、画像のリンクも取得しておく必要があります。
実際にサムネイルを取得できているかどうかは、「Preview」で確認できます。
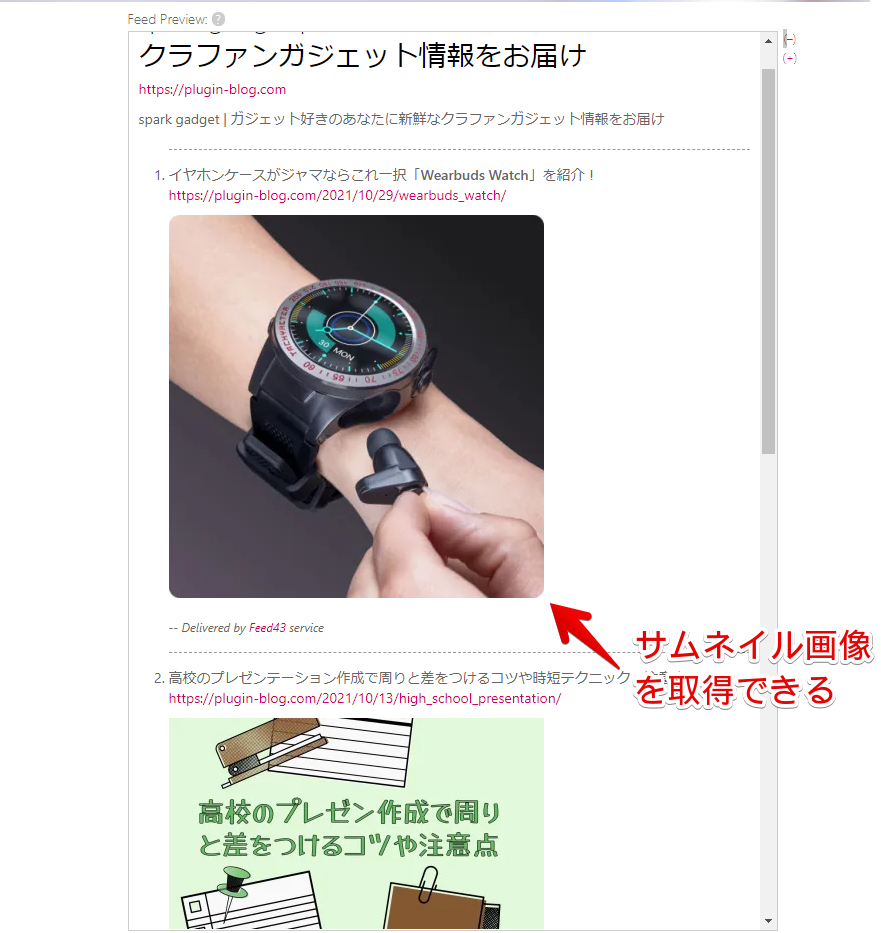
「spark gadget」だと、下記のようになります。
HTML変換前
data-layzr="https://i0.wp.com/plugin-blog.com/wp-content/uploads/2022/01/rakunew-サムネイル.png?fit=768%2C432&ssl=1" class="attachment-icatch768 size-icatch768 wp-post-image" alt="rakunew-サムネイル" /></a></div><div class="archive__contents"><ul class="dateList"> <li class="dateList__item icon-update">1月 16, 2022</li> </ul> <h2 class="heading heading-secondary"> <a href="https://plugin-blog.com/2022/01/13/rakunew-introduction/">海外クラウドファンディングが英語で困ってる方は海外通販「Rakunew」でガジェットを購入しよう!</a> </h2> <p class="phrase phrase-secondary">どうも、こんにちは、こんばんわ、最近、ネットで買ったガジェットの配達が鳴り止まない、ちむ(@timuuuuuu009)です。 そ […] </p> </div>HTML変換後
data-layzr="{%}"{*}<li class="dateList__item icon-update">{%}</li> </ul> <h2 class="heading heading-secondary"> <a href="{%}">{%}</a> </h2> <p class="phrase phrase-secondary">{%}</p> </div>Item Content Template
<img src="{%1}">サムネイルサイズが大きい場合は、幅を指定して調整できます。
<img width=300px src="{%1}">「h2」なども利用できます。
<img width=300px src="{%1}">
<h3>{%2}</h3>
{%5}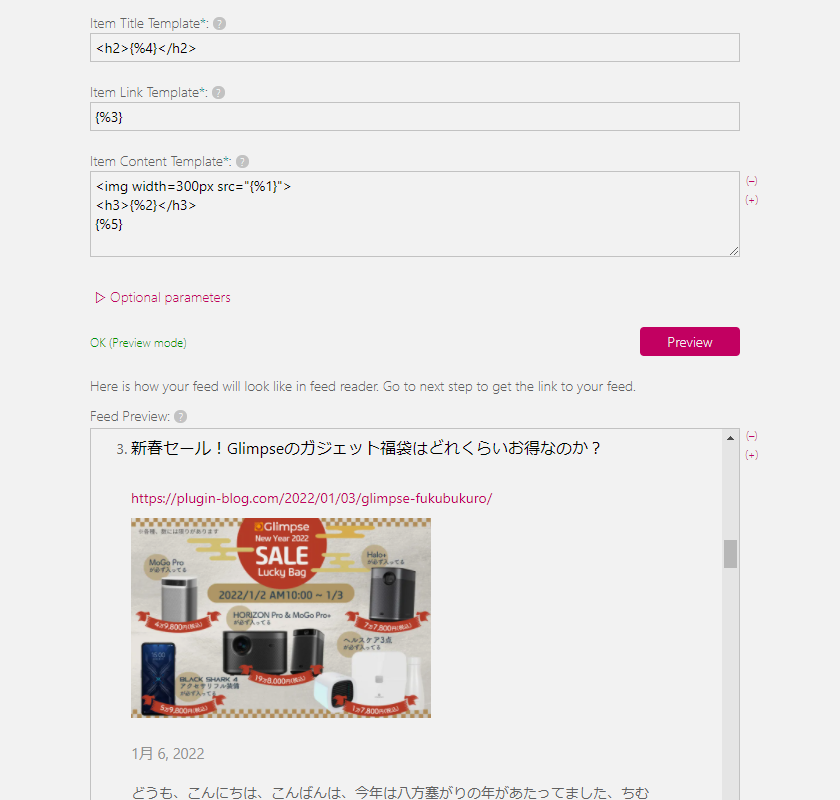
入力できたら、「Preview」をクリックします。フィードのプレビューが表示されます。記事タイトル、記事リンクごとになっていたら成功です。
パラメーターの部分は、好きな固定文字と組み合わせることもできます。サイトタイトルを冒頭につけるといった感じです。
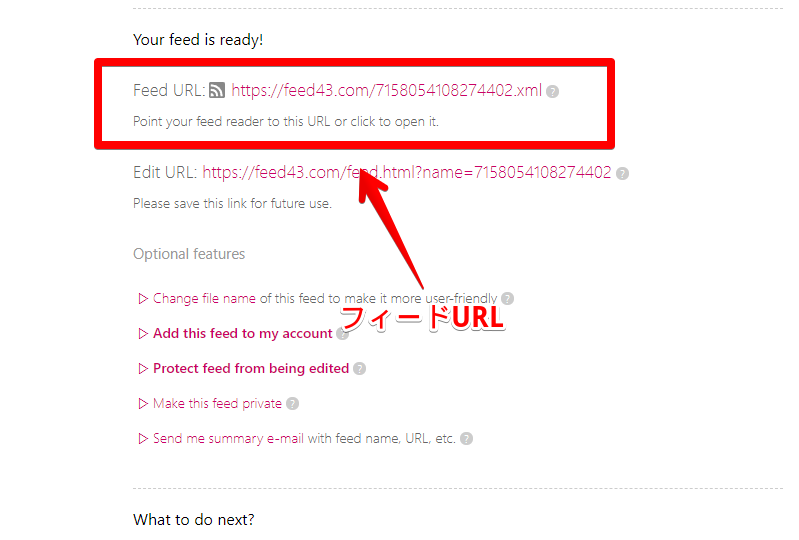
フィードの購読
プレビューを作成したら、ページ下に「Your feed is ready!」の項目が表示されます。「Feed URL」が実際のフィードURLです。右クリック→「リンクアドレスをコピー」をクリックします。
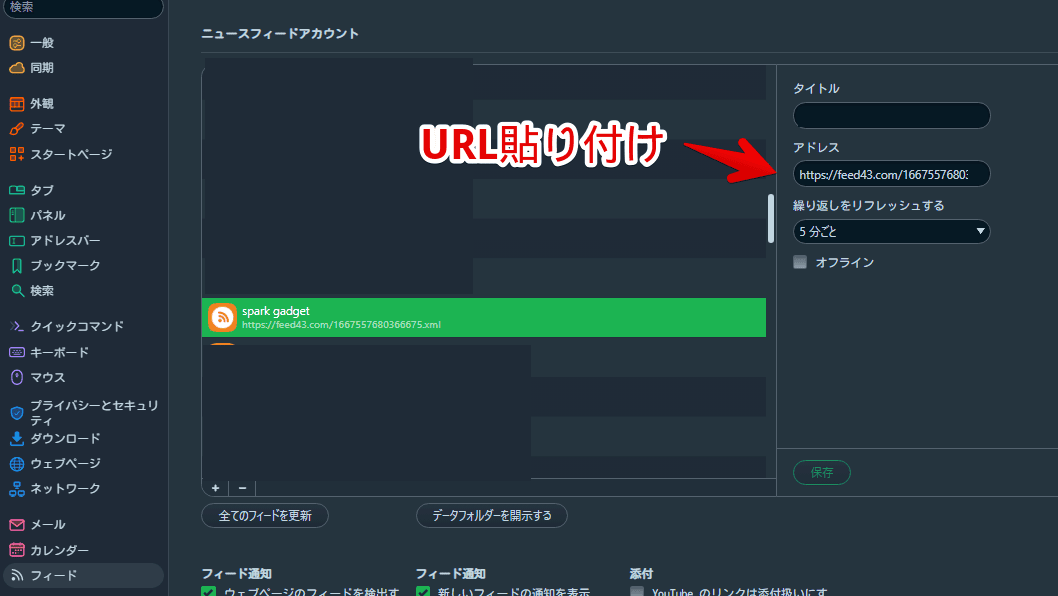
フィードリーダー(例:「feedly」など)に登録します。本記事では、例として、「Vivaldi(ヴィヴァルディ)」ブラウザに登録してみます。アドレスの部分にコピーしたURLを貼り付けます。タイトルは、Feed43で設定したので、空欄でOKです。
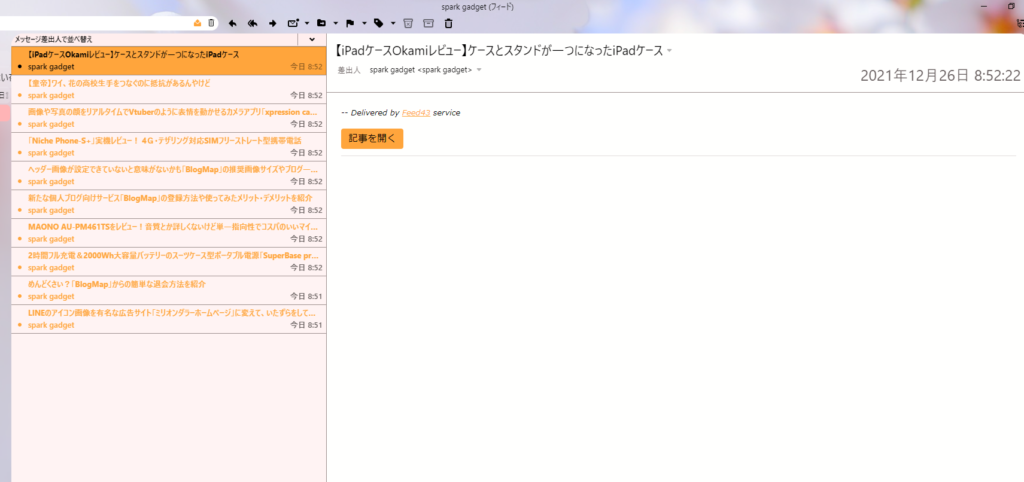
Enterで登録すると、自動でタイトルが取得されます。RSSフィードの購読完了です。初回の購読時は、一気に過去記事が届きます。
余談ですが、Vivaldiのフィードリーダーには、サイトにアクセスしなくても、記事内容を確認できる便利な機能が搭載されています。しかし、Feed43で作成した場合は、動作しません。あくまで記事タイトル、記事URLのみの取得です。
感想
以上、RSS非対応サイトのフィードを作成できるサービス「Feed43」についてでした。
ブログを運営していると、ソフトの更新情報や、他の方のブログを通知してほしい時が結構あるので、非対応サイトでも購読できるのは便利です。